大規模地方議会会議録の分散表現 (word2vecモデル) の公開
共通パラメータ等
| パラメータ名 | 値 |
|---|---|
| トークン化 | Comainu |
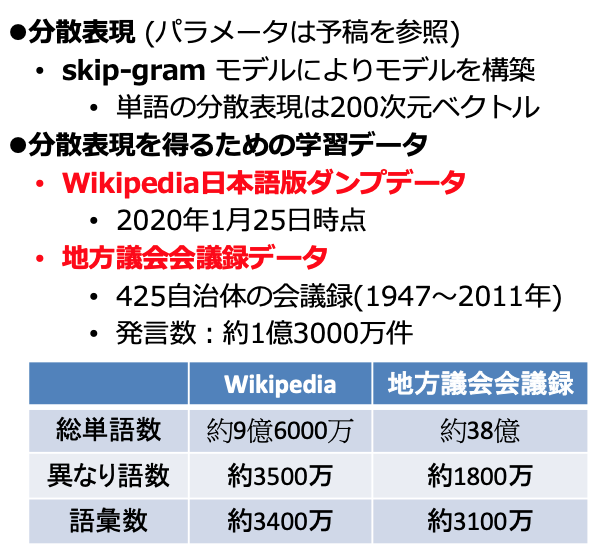
| size | 200 |
| window | 5 |
| negative | 5 |
| min_count | 5 |
| sg | 1 (skip-gram) |
| hs | 0 |
| iter | 20 |

分散表現(Comainuで単語分割したもの)
地方議会会議録Word2vecモデル(xz圧縮 2.5GB)
日本語WikipediaWord2vecモデル(xz圧縮 2.7GB)
ダウンロード方法
http://local-politics.jp/word2vec/
(w2v と jsai2020) を入力する
参考文献
JSAI2020 [4Rin1-59] 大規模地方議会会議録の分散表現を用いた地方議会のトピック分析
〇佐々木 稔1、乙武 北斗2、木村 泰知3
(1.茨城大学、2.福岡大学、3.小樽商科大学)
キーワード:地方議会会議録、分散表現、トピック分析、データ公開
本研究では,地方議会会議録に対して,地方議会でどのような話題が議論されているかについてテキストマイニング手法を利用した分析を行う.既存研究では話題の分析を行う際に,最も適切な単語単位はどの程度なのか,大規模な都道府県議会会議録から得られた単語の分散表現が利用可能なのかについて研究が行われていない.本稿では,NTCIR14 Segmentation task で利用されたデータセットを用いて,単語分割や学習データの違いにより,トピックモデルの結果がどの程度異なるのかについて分析を行った.その結果,単語分割については,Comainu を用いたことにより,固有名詞や複合名詞を扱えるようになり,トピックの意味が理解しやすくなり,ラベル付けが容易できることを確認した.学習コーパスについては, 地方議会会議録を学習データとした分散表現を用いることで,細かな表現に対応できるこ可能性があることを確認した.しかしながら,異なる分散表現を用いたときのトピックには明確な違いを確認することができなかった.